Файл robots.txt - это файл, который похожий на забор вокруг вашего двора. Некоторые заборы позволяют вам видеть, а другие построены, чтобы все убрать. Файл robos.txt находится в корневом каталоге вашего веб-сайта и указывает, какие части вашего веб-сайта вы используете или не хотите, чтобы поисковые роботы просматривали или получали доступ. Только этот файл, обычно весом не более нескольких байтов, может нести ответственность за создание или нарушение отношений вашего сайта с поисковыми системами.
Возможно, вы захотите заблокировать роботов от индексирования частных фотографий, специальных предложений или других страниц, которые вы не готовы для доступа к пользователям. Блокирующие страницы также могут помочь вашему SEO. Robots.txt может решить проблемы с дублирующимся контентом, однако могут быть более эффективные способы сделать это. Когда робот начинает сканирование, они сначала проверяют, установлен ли файл robots.txt, который не позволит им просматривать определенные страницы.
Robots часто встречается в корневом каталоге вашего сайта и существует для регулирования ботов, которые сканируют ваш сайт. Здесь вы можете предоставить или запретить разрешение всем или некоторым конкретным роботам поисковых систем для доступа к определенным страницам или вашему сайту в целом.
Когда следует использовать файл Robots.txt
Необходимо использовать файл robots.txt, если вы не хотите, чтобы поисковые системы индексировали определенные страницы или контент. Если вам нужны поисковые системы, например, Google, Bing и Yahoo, где для доступа и индексации всего вашего сайта, вам не нужен файл robots.txt, также в некоторых случаях люди используют файл robots, чтобы указать пользователям на карта сайта.
Однако, если другие сайты ссылаются на страницы вашего сайта, заблокированные robots.txt, поисковые системы могут по-прежнему индексировать адреса, и они могут отображаться в результатах поиска. Чтобы этого не произошло, используйте метку x-robots-tag, noindex meta tag или rel canonical на соответствующую страницу.
Причины, по которым вам может понадобиться файл robots.txt:
1. У вас есть контент, который вы хотите заблокировать из поисковых систем; 2. Вы разрабатываете сайт, который является живым, но вы не хотите, чтобы поисковые системы его индексировали; 3. Вы хотите точно настроить доступ к вашему сайту от авторитетных роботов; 4. Вы используете платные ссылки или рекламные объявления, для которых требуются специальные инструкции для роботов; 5. Они помогают вам следовать некоторым рекомендациям Google в некоторых ситуациях;
Причины, по которым вы не хотите иметь файл robots.txt:
1. Ваш сайт прост и свободен от ошибок, и вы хотите, чтобы все индексировалось; 2. У вас нет файлов, которые вы хотите или их нужно заблокировать из поисковых систем; 3. Вы не попадаете в ситуации, перечисленные выше, чтобы иметь файл robots.txt; 4. Это нормально, если у вас нет файла robots.txt;
Если у вас нет файла robots.txt, поисковые роботы, такие как Googlebot будут иметь полный доступ к вашему сайту. Это обычный и простой метод, который очень распространен.
Включение Robots.txt для улучшения SEO
Теперь, когда вы понимаете этот важный элемент SEO, проверьте свой собственный сайт, чтобы поисковые системы индексировали страницы, которые вы хотите, и игнорируете тех, кого хотите оставить вне результатов поиска. В дальнейшем вы можете продолжать использовать robot.txt для информирования поисковых систем о том, как они сканируют ваш сайт.
Блокирование дублирующегося содержимого
Вы можете исключить любые страницы, содержащие дублирующийся контент. Например, если вы предлагаете «печатные версии» некоторых страниц, вам не нужно, чтобы Google индексировал повторяющиеся версии, поскольку дублирующийся контент мог повредить вашему ранжированию.
Однако имейте в виду, что люди все еще могут посещать и ссылаться на эти страницы, поэтому если информация является типом, который вы не хотите видеть другим, вам необходимо использовать защиту паролем, чтобы сохранить его конфиденциальным. Это потому, что, вероятно, есть некоторые страницы, содержащие конфиденциальную информацию, которую вы не хотите показывать в SERP.
Как создать файл Robots.txt
Если хотите настроить файл robots.txt, процесс на самом деле довольно прост и включает в себя два элемента, это пользовательский агент, что является роботом, что применяется следующий блок URL, который вы хотите заблокировать. Эти две строки рассматриваются как одна запись в файле, что означает, что вы можете иметь несколько записей в одном файле robots.txt.
Для строки пользовательского агента вы можете указать конкретный бот или применить блок URL ко всем ботам, используя звездочку. Ниже приведен пример пользовательского агента, блокирующего все боты.
User-agent: *
Вторая строка в записи, то она перечисляет конкретные страницы, которые вы хотите заблокировать. Чтобы заблокировать весь сайт, используйте косую черту. Для всех других записей сначала используйте косую черту, а затем перечислите страницу, каталог, изображение или тип файла.
Следующие примеры:
Disallow: / блокирует весь сайт.
Disallow: /bad-directory/ блокирует как каталог, так и все его содержимое.
Disallow: /блокирует страницу.
После создания вашего пользовательского агента и запрета выбора, одна из ваших записей может выглядеть так:
User-agent: * Disallow: /bad-directory/
Сохраните файл, скопировав его в текстовый файл или блокнот и сохраните как «robots.txt». Обязательно сохраните файл в каталоге самого высокого уровня вашего сайта и убедитесь, что он находится в корневом домене с именем, точно совпадающим с robots.
Как это работает
Проверьте файл robots.txt вашего сайта в инструментах для вебмастеров, чтобы убедиться, что боты сканируют части сайта, который вы хотите и избегаете заблокированных вами областей.
1. Выберите сайт, который вы хотите проверить; 2. Нажмите «Заблокированные URL адреса» в разделе Сканирование; 3. Выберите вкладку Test robots.txt; 4. Вставьте содержимое вашего robots.txt в первый блок; 5. Перечислите сайт для проверки в поле адреса; 6. Выберите пользовательские агенты в списке пользователь агенты;
Имейте в виду, что это проверит только робота Googlebot и других пользовательских агентов Google. Вы можете использовать robots для блокировки файлов ресурсов, таких как неважные изображения, сценарии или файлы стилей. Имейте в виду, если эти файлы необходимы для рендеринга вашего сайта, это может повлиять на доступность вашего сайта. Если файлы заблокированы, искатель не загрузит их, даже если вызывается на странице.
Файл robots.txt веб-сайта находится по адресу http: //сайт/robots.txt . Веб-сайт с по умолчанию robots.txt индексируется наилучшим образом - мы настраиваем файл таким образом, чтобы индексировались только страницы с контентом, а не все существующие страницы, например, страница входа или регистрации. Поэтому сайты uCoz индексируются лучше и получают более высокий приоритет по сравнению с другими сайтами, где индексируются все ненужные страницы.
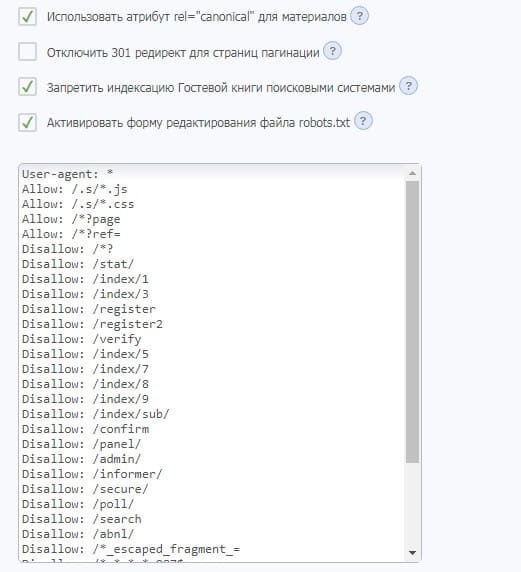
User-agent: * общее обращение ко всем сканерам, читающим файл robots.txt Allow: /*?page разрешение страниц пагинации на главных страницах модулей (связанно со строчкой Disallow: /*? ) Allow: /*?ref= нужна для правильной переиндексации компонентов социальной регистрации Disallow: /*? запрет к индексации поисковых запросов, кода безопасности на uCoz, проксированных ссылок, компонентов рекламного баннера, дублей главной страницы и блога (компоненты кода системы, связанные с сессиями ssid), дубли ссылок на изображения в фотоальбомах, других мусорных компонентов системы Disallow: /stat/ запрет индексации компонента счетчика статистики (картинка с данными) Disallow: /index/1 техническая страница входа Disallow: /index/3 запрет индексации страницы регистрации (локальная регистрация) Disallow: /register запрет индексации страницы регистрации (социальная и uID регистрация) Disallow: /index/5 запрет к индексации аякс окна напоминания пароля в старой форме входа Disallow: /index/7 служебная страница выбора аватара из коллекции Disallow: /index/8 запрет к индексации профилей пользователей (один из способов защиты от спама) Disallow: /index/9 запрет индексации аякс окна Доступ запрещен Disallow: /index/sub/ запрет к индексации локальной авторизации (связано со старой формой входа) Disallow: /panel/ запрет к индексации входа в панель управления Disallow: /admin/ запрет к индексации входа в панель управления Disallow: /informer/ запрет к индексации информеров, вставленных скриптом (при этом содержимое информеров, вставленных системным кодом $MYINF_х$ будет индексироваться свободно) Disallow: /secure/ запрет на индексацию кода безопасности (связано со строчкой Disallow: /*?) Disallow: /poll/ запрет индексации служебной папки опросов Disallow: /search/ запрет индексации страницы поиска, тегов и поисковых запросов (связано со строчкой Disallow: /*?) Disallow: /abnl/ запрет индексации компонентов системного рекламного баннера (для сайтов с не отключенной рекламой) Disallow: /*_escaped_fragment_= запрет технического компонента кода Disallow: /*-*-*-*-987$ запрет дублей страниц в модулях Новости и Блог, связанных с кодом комментариев на странице Disallow: /shop/checkout/ запрет к индексации корзины и кода оформления заказа для Интернет магазина Disallow: /shop/user/ запрет к индексации пользователей магазина (субагенты) Disallow: /*0-*-0-17$ запрет к индексации различных фильтров, страниц материалов пользователя, ссылки на последнее сообщение форума, дублей системы и т.д Disallow: /*-0-0- запрет к индексации страниц добавления материалов, списков материалов пользователей, ленточного варианта форума (некоторые дублирующие URL), страниц со списком пользователей (некоторые дублирующие URL), поиска по форуму, правил форума, добавления тем на форуме, различные фильтры (с дублями), страницы с редиректами на залитые на сервер файлы Sitemap: //адрес сайта/sitemap.xml общая карта сайта Sitemap: //адрес сайта/sitemap-forum.xml карта форума (оставлять в файле, если активирован модуль форум) Sitemap: //адрес сайта/sitemap-shop.xml карта магазина (прописывать только, если активирован модуль Интернет магазин) Host: адрес сайта без https:// (прописывать, если прикреплен домен для определения главного зеркала. дирректива прописывается в любом месте роботса, предназначена для Яндекса, при этом отдельное обращение к роботам Яндекса не нужно. Google игнорируется)
Информеры не индексируются, потому что они отображают информацию, которая УЖЕ существует. Как правило, эта информация уже проиндексирована на соответствующих страницах.
[info]Вопрос: Я случайно испортил robots.txt. Что мне делать?
Ответ: Удалите его. Файл robots.txt по умолчанию будет добавлен автоматически (система проверяет, есть ли у него сайт, а если нет - добавляет обратно файл по умолчанию).[/info]
[info]Вопрос: Существует ли какое-либо использование при отправке веб-сайта в поисковые системы, если карантин еще не удален?
Ответ: Нет, ваш сайт не будет индексироваться во время карантина.[/info]
[info]Вопрос: Будет ли автоматически заменен файл robots.txt после удаления карантина? Или я должен обновить его вручную?
Ответ: Он будет обновляться автоматически.[/info]
[info]Вопрос: Можно ли удалить файл robots.txt по умолчанию?
Ответ: Вы не можете удалить его, это системный файл, но вы можете добавить свой собственный файл. Однако мы не рекомендуем это делать, как было сказано выше. Во время карантина невозможно загрузить собственный файл robots.txt.[/info]
[info]Вопрос: Что мне делать, чтобы запретить индексирование следующих страниц?
Можно добавить в самом начале файла роботс перед всем содержимым директиву с доступом для мобильного робота гугла:
Код
User-agent:Googlebot-Mobile Allow: /
Это позволит мобильному роботу без проблем сканировать ваш сайт.
Далее:
С наших рекомендаций, после директив с доступом индексировать изображения сайта, стоит и добавить доступ к индексации шрифтов на сайте, чтобы роботы имели полный доступ к сайту и корректно его видели с шрифтами, которые на сайте подключены.
Это существенно улучшит отображение вашего сайта для поисковиков и они будут корректно видеть сайт с вашими шрифтами.
Далее
В дополнение, было замечено по отчетам с индексации яндекса, что робот посещает страницу регистрации и находит сгенерированные урл подобно /confirm/ и индексирует их. Для решения данной проблемы рекомендую в роботс добавить директиву:
[info]Disallow: /confirm/[/info]
Это сохранит ваш сайт от индексации мусора.
И крайнее изменение
Если вы не используете модуль Интернет-магазин, с файла роботс можно удалить следующие директивы:
Обновил robots.txt - где добавил некоторые элементы, где ниже будет описание. Здесь хотелось узнать, правильно или нужно как то по другому.
Kosten, важно понимать, что директивы в файл robots.txt прописываются, чтобы запретить доступ роботу к чему-то (или наоборот разрешить). Когда там прописано много директив, то он больше времени тратит на разбор.
ЦитатаKosten ()
Allow: /*.js Allow: /*.css
Поменять на:
Код
Allow: /.s/*.js Allow: /.s/*.css
Ведь там системные скрипты и стили после обнов делаются с прописанной версией (?v), а остальные на сайте и так разрешены для индексации.
ЦитатаKosten ()
Allow: /*.jpg Allow: /*.png Allow: /*.gif
Лишнее, поскольку нет модуля фотоальбом. У кого включен, то там выводятся уменьшенные копии изображений - в пути к ним идет ? и дальше цифры (вот и прописывается Allow для картинок, чтобы перекрыть директиву Disallow: /*?).
ЦитатаKosten ()
Allow: /*?ref=
Лично я советовал бы убрать (и убираю у себя). Не раз уже замечал, что пока разрешено, то загоняются "левые" ссылки (пример).
Можно убрать. Через инструмент проверки robots.txt того же Яндекса проверить ссылки на шрифты, что у вас указаны в стилях. То есть они и так не запрещены для индексации. Разве что оставить строчку Allow: /*.eot (в стилях идёт /.s/t/1321/fonts/PTS55F_W.eot?#iefix - то есть опять для противодействия директиве Disallow: /*? ... но файл и так просканирует, ведь есть ссылка без ? на этот шрифт).
ЦитатаKosten ()
Disallow: /confirm/
Как-то не встречал, чтобы это роботом обходилось (надо будет проверить у себя в Вебмастере). Описание смутило, если честно (ведь страница регистрации как раз запрещена для индексации). Как понял, то эта ссылка появляется для подтверждения e-mail пользователями. UPD.: не нашёл на сайте с локальной базой пользователей (а может из-за того, что там вход идёт всегда через /index/1), ну а на другом сайте с uID-поддержкой и социальным входом - есть такая фигня, соответственно запрет дописан был.
ЦитатаKosten ()
Disallow: /poll/
Это нужно, если включен блок опросов. У вас в коде его нет, посему можно убрать (если поисковый бот где-то всё же найдёт ссылку на опросы у вас на сайте, то тогда уж и вернете запрет).
ЦитатаKosten ()
Disallow: /search/
Можно сразу Disallow: /search (чтобы всю страницу, а не только результаты поиска). Один фиг, что для ПС там нет ничего интересного (эта страница не оптимизирована для них).
ЦитатаKosten ()
Disallow: /*-0-0-
Кто не знал, то для этой директивы они дают не совсем правильное пояснение у себя на оф. форуме, о чём уже говорил. Хорошо, что в руководстве хоть исправили, что эта директива не "Запрещает индексацию" "страницы с редиректами на ссылки на скачивание с удаленного сервера" (если еще на стороне системы не поставили там запрет, то нужно хотя бы у ссылки на удаленное скачивания сделать rel="nofollow" прямо у себя в шаблоне). Также по своему опыту скажу, что можно дописать:
Код
Disallow: /forum/*-0-*0-1
В своё время помогло решить проблему обхода роботом (Яндекс) ненужных страниц форума (всякие поисковые запросы, фильтры).
ЦитатаKosten ()
на Sitemap убрал http
Там не нужно было (и увидел, что вернули уже - правильно). Протокол убирать, если сайт по https работает (и убрано принудительное перенаправление на него, как понял). Нужно роботу сразу указывать протокол в адресе, который продвигается (ну и соответственно, если сайт будет с ssl, то пишется тогда Host: https://zornet.ru).
Помог? Скажи спасибо в виде "+" - вам мелочь, а мне приятно. Бесплатное оказание помощи в ответах на "Вопросы про uCoz".
Сообщение отредактировал -SAM- - Воскресенье, 03 Октября 2021, 03:31
Здесь полностью согласен, где нужно закрыть, ведь не раз уже замечал, что ссылки индексируются.
В этом случае не закрываем, а наоборот открываем (и только то, что не индексируется). А не накидать кучу разрешающих директив на то, что и так индексируется (или вообще чего нет на сайте). В общем, всё выше расписал уже.
Disallow: /forum/*-0-*0-1 - это следует включить в том случае, если есть непонятные ссылки на темы форума (с поисковыми словами-фильтрами).
UPD.:
ЦитатаKosten ()
Это - то что на других форумах могут ссылку на этот сайт прописать - так понял.
Причём здесь другие форумы? Директива для запрета обхода ненужных страниц на этом форуме. В любом случае, то оно неактивно же (закомментировано через #). В прошлом наблюдал картину, что робот Яндекса ходил по этим ссылкам, посему закрыл. Возможно, что уже пофиксили это (в самой системе uCoz), что директива не нужна. И я примера не вспомнил таких ссылок, как и не нашёл уже их в Вебмастере (если найду, то скину). То есть вам нужно проверять раздел "Страницы в поиске" Я.Вебмастер (там фильтры сделать и посмотреть, есть ли попытки обхода страниц с подобными адресами).
Помог? Скажи спасибо в виде "+" - вам мелочь, а мне приятно. Бесплатное оказание помощи в ответах на "Вопросы про uCoz".
Сообщение отредактировал -SAM- - Вторник, 05 Октября 2021, 20:33
Kosten, на ZorNet нет этого модуля, посему директива попросту убирается (выше писал про это всё). Изменения делаются в том случае, если используется свой файл robots.txt, что директивы прописанные отличаются от системных. У кого файла нет залитого, то система сама генерирует актуальный файл robots.txt. В общем, оно не касается тематики, это системные правки файла.
Если брать текущий файл на ZorNet, то он практически не отличается от системного (можете убедиться в этом сами, попросту посмотрев здесь, к примеру, где актуальный файл генерирует система сама). Мы лишь сократили его за счёт того, что нет всех модулей - здесь нет мини-чата, нет фотоальбома, нет и-нет магазина (в общем, по умолчанию система прописывает наперед все директивы, даже когда модуль еще не активирован).
И что касается вот этого:
Код
User-agent: Googlebot-Mobile Allow: / Disallow:
Можно убрать тоже, как писал выше. Поскольку мы даём разрешение на обход сайта этому роботу, а дальше идёт разрешение на обход всеми роботами. То есть, если бы были свои запрещающие директивы для обхода Googlebot-Mobile, то пропись нужна была бы, а так - директивы отсутствуют. И вот эту строчку:
Код
# Disallow: /forum/*-0-*0-1
Можно убрать, ведь всё равно она же сейчас не функционирует из-за прописанного # (то есть это как текст-комментарий идёт просто). Как выше писал, что строчка возможно понадобиться, когда в индекс залетал бы мусор на форуме по этому адресу (как видно, что с этим нет проблем... либо тогда была проблема конкретно на сайте, на котором я прописывал, либо же в системе исправили уже).
Помог? Скажи спасибо в виде "+" - вам мелочь, а мне приятно. Бесплатное оказание помощи в ответах на "Вопросы про uCoz".
Сообщение отредактировал -SAM- - Пятница, 22 Июля 2022, 04:03
Лучше не лксти, пока нормально, но если не трудно, -SAM-, можете прописать правильный какой правильный, просто когда по мелочи меняю, всегда что то не так, как и сейчас)))